重置 HomePod min
1、拔掉电源线,等待10 秒后再插回去
2、等候5 秒后按压HomePod mini 顶部
3、此时顶部的光会由白色转回红色
4、当你听到三次哔声后,即表示重置完成。
1、拔掉电源线,等待10 秒后再插回去
2、等候5 秒后按压HomePod mini 顶部
3、此时顶部的光会由白色转回红色
4、当你听到三次哔声后,即表示重置完成。
注意:如果你使用的是带HDMI的桌面版,一定要选择一个电流足够的适配器,否则会导致异常重启。
sudo passwd root
sudo nano /boot/config.txtdisplay_hdmi_rotate=2sudo systemctl enable ssh
sudo systemctl start ssh系统默认python3,有时候你需要运行的项目是python2的,我们需要pyenv
git clone https://github.com/pyenv/pyenv.git ~/.pyenv
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.profile
echo 'export PATH="$PYENV_ROOT/libexec:$PATH"' >> ~/.profile
echo 'eval "$(pyenv init --path)"' >> ~/.profile
echo 'eval "$(pyenv init -)"' >> ~/.bashrc
exec $SHELL -l
On the other hand, the BCM2835 uses a single core and thread 32-bit microprocessor. Once again, it features a clock speed of 700 Mhz. However, it has a turbo capability to boost clock frequencies up to 1 GHz. Unfortunately, this feature is absent from the BCM2711.The BCM2835 is an SoC that Broadcom Semiconductors developed. As we have briefly mentioned in the introduction, SoC packages such as the BCM2835 make devices such as the Raspberry Pi Zero possible. Additionally, The Raspberry Pi Foundation features the BCM2835 in the Raspberry Pi A, A+, B, B+, and the Raspberry Pi Zero W. Moreover, you can find it in rare models such as the Raspberry Pi Compute Module 1.
Since it’s an older chip package, you’re unlikely to find it in newer microcontrollers or single-board computers. However, its capabilities and peripherals are still worth exploring.准备大于8G的SD
根据前面的介绍,我们知道我们的板子是32架构,所以我们要选择32bit的系统:
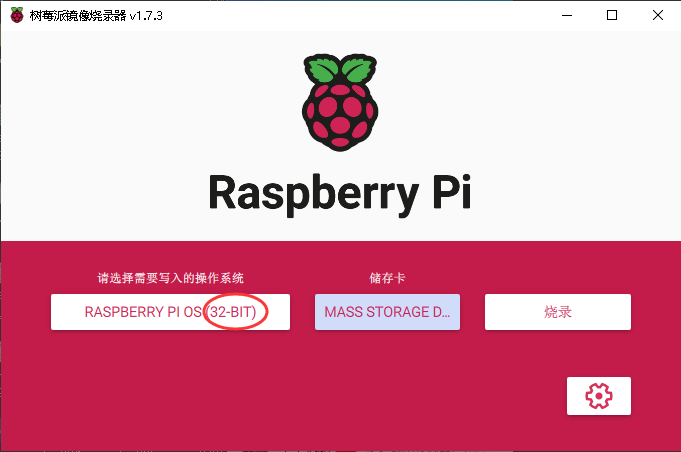
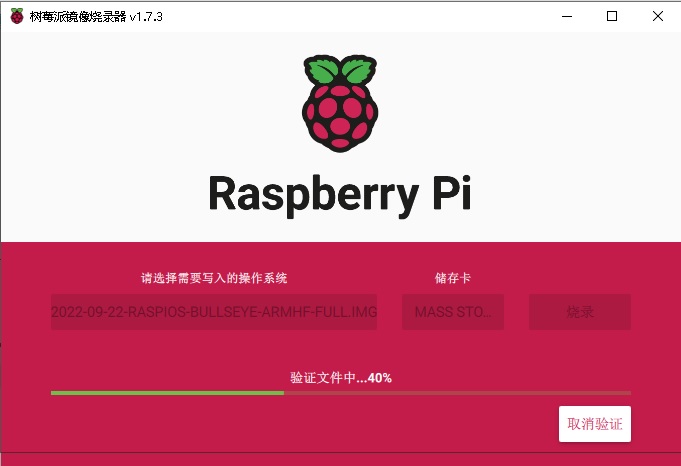
说明:
经过耐心的等待,就会提示校验成功,可以拿下sd插入设备了。
关于镜像存储功能简单总结:自动回源,切换无拷贝工作量,且只回源一次,在某些源不稳定的架构中,非常有用。
主要做以下几步:
在对象存储-》空间管理里面,创建一个空间。
加速域名其实就是你想镜像的内容入口。
这里主要就是回源地址,这里非常有用的是支持端口,你懂的,内网资源呵呵呵。
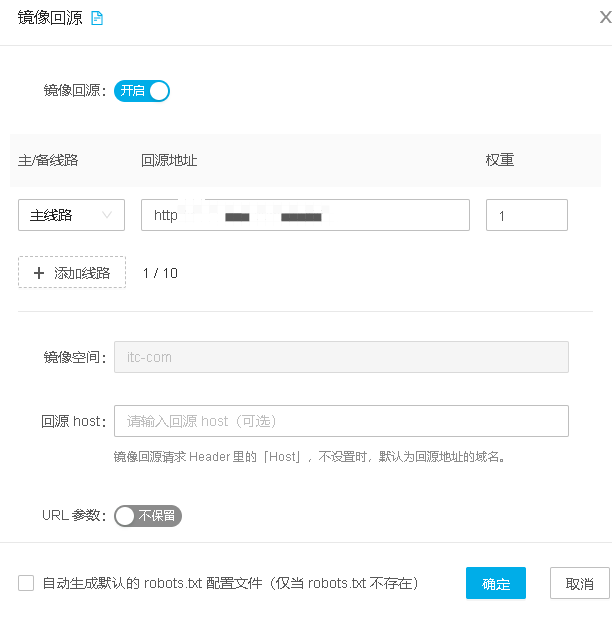
做好以上设置,功能就基本可用了,至于其他高级数据,再按需开启。
最后需要说明的是,镜像服务是一种cdn服务,是收流量费的,在方便和钱之前,还是要实际斟酌调试的。
ldd a.so可以检查a的依赖,但是因为ldd要链接a.so,所以在本机环境正常,但是当是交叉编译的目标时,就不行了。
这时候可以用objdump来检查了:
objdump -x a.so |grep NEEDED
我们知道在ffmpeg已经有了很多lib,比如avcode avdevice avutil等。
如果我们要现有的makefile框架中新增加一个lib叫做a.so,该如何修改?
本文基于ffmpeg4.3.4,如果验证版本有变,请自行调整。
NAME = a
DESC = FFmpeg new demo library
HEADERS = a.h version.h
OBJS = a.oFFLIBS := avutil a# this list should be kept in linking order
LIBRARY_LIST="
avdevice
avfilter
swscale
postproc
avformat
avcodec
swresample
avresample
avutil
a
"ALLFFLIBS = avcodec avdevice avfilter avformat avresample avutil postproc swscale swresample a至此,只要a配置正确的makefile就应该能正确编译了。
上面介绍了如何扩展lib,假如ffmpeg原有的lib 叫 x.so, 我们二次开发了一个基于x.so的 a.so, 那么如何让a.so能正确调用到x.so?
configure:
# libraries, in any order
avenc_deps="ava"说明上面的av是沿用ffmpeg默认命令习惯
TOOLS_DIR=toolchain/bin
./configure --enable-shared \
--disable-static \
--disable-x86asm \
--enable-cross-compile \
--strip=$TOOLS_DIR/llvm-strip \
--extra-cflags="-I$(pwd)/install/include" \
--extra-ldflags="-L$(pwd)/install/libs" \
--prefix=$(pwd)/install \
--target-os=linux \
TOOLS_DIR=ndk-toolchain/bin
./configure --enable-shared \
--disable-static \
--disable-x86asm \
--enable-cross-compile \
--cc=$TOOLS_DIR/armv7a-linux-androideabi26-clang \
--cxx=$TOOLS_DIR/armv7a-linux-androideabi26-clang++ \
--strip=$TOOLS_DIR/llvm-strip \
--extra-cflags="-I$(pwd)/install/include" \
--extra-ldflags="-L$(pwd)/install/libs" \
--arch=arm \
--prefix=$(pwd)/install \
--target-os=android \当我们想定制入网优先级,或者在多漫游网络中想选择较为理想信号强度的时候,就可能用到xPLMNs。
需要说明的是,部分plmn是在sim中的,能不能定制修改,跟开卡的套餐和运营商发卡的限制有关,需要实际测试。
所有的细节都在3GPP的标准中有详细说明,可以自行查阅。
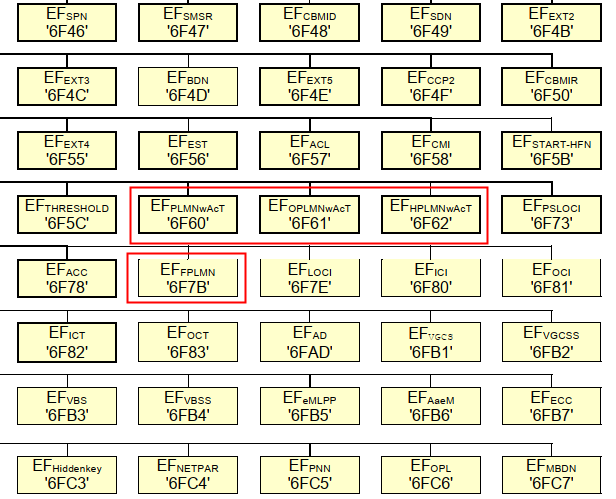
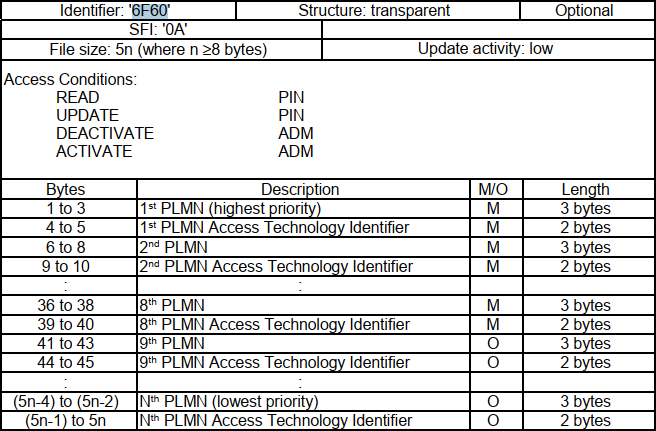
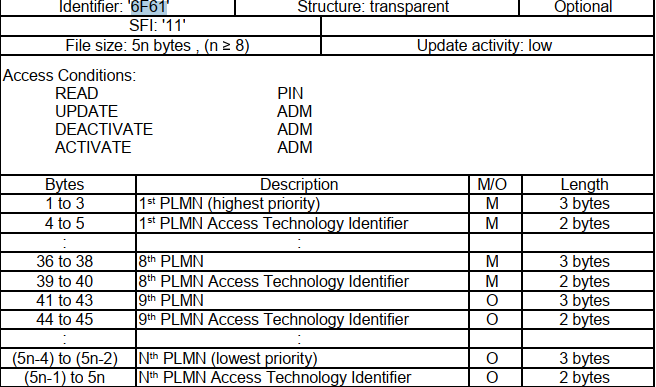
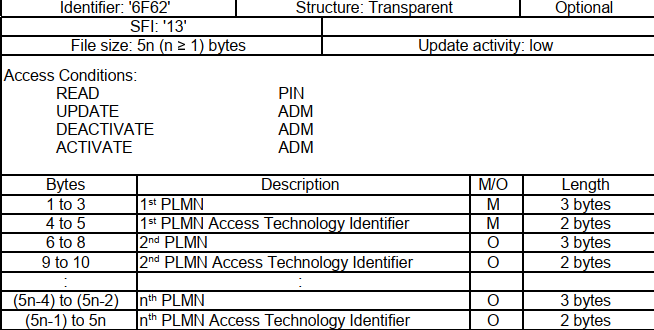
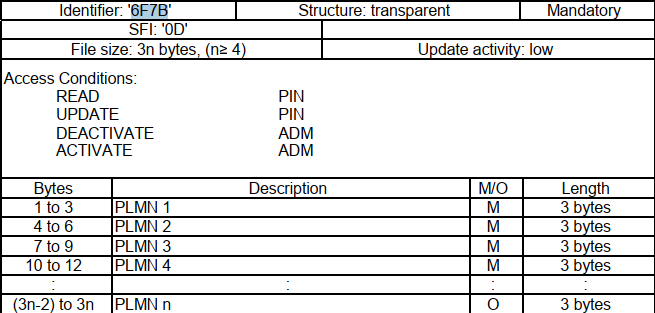
我们经常看到uplmn用户自定义plmn,优先级高于oplmn,参考概述图,我们并没有看到uplmn的说明。
参考以下的内容:
The OPLMN is formally known as the ‘OPLMNwAcT’, and the UPLMN as the ‘PLMNwAcT’. The ‘wAcT’ in each case is short for ‘with Access Technology’所以,uplmn 实际就是 PLMNwAcT=0x6F60=28512
参考ref:
刚开始只想更换电池,因为电池掉到80%以下了,基本一天两三充。但是拆机过程中把屏幕不小心搞废了,正好以前手机也摔过,屏幕有印痕黑块,所以很痛快就想一起换了。
这个是整个更换中最难的部分,估计也是很多人容易搞砸的地方。
刚开始没搞明白拆屏幕的细节,也没有网上的抬屏工具,基本是凭经验用风枪和刀片弄的,结果硬生生把屏幕从中间拆开了(有点虎):



移除以上部位的固定螺丝后,就可以把屏幕和电池拆卸下来了。
需要注意的是拆卸电池要小心,不要用金属戳,避免电池短路自燃
新买的屏幕总成是没有喇叭部分的,需要移植旧屏幕上的部分,注意的是记得要把胶托移过来,这样支撑和音腔效果才能好:

拆除成功后,先装屏幕,然后再装电池,测试系统开机正常。如果不能开机或者功能不正常,逐个检查fpc座子。
测试通过后,开始加装盖板和螺丝。

最后一步就是贴胶膜,主要是防水:

红色的一圈就是胶膜,贴好后,撕掉塑料,然后把屏幕装进去,轻轻的一圈压好,再锁底部的两个螺丝。
电池和屏幕都正常。
GPon是之际可以ppoe拨号的,为了使用自己路由器的一些功能,所以想用自己的拨号,实质上也是有差异的比如NAT的支持效果等。
很早就改成自己路由器了,最近因为想改家庭网络配置又改成gpon了,然后发现效果不好又想改回去,就死活也配置不成功了,浪费了一上午,所以记录下,避免下次再吃瘪。
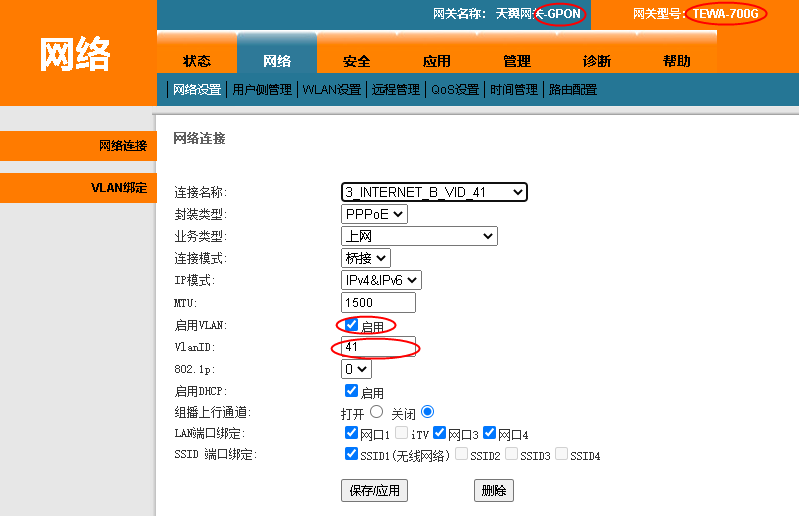
这里重要的几个点:
需要说明的是,配置好了后,经过验证是不需要vlan绑定的。